More efficient way to do outer join with large dataframes
16 Apr 2020Today I learned from a colleague the way of doing outer join of large dataframes more efficiently: instead of doing the outer join, you can first union the key column, and then implement left join twice. I have done an experiment myself on the cluster with two dataframes (df1 and df2) - each dataframe has ~10k rows, and there is only ~10% of overlap(i.e. an inner-join would result in ~1k rows).
The usual way of doing outer join would be like:
df3 = df1.join(df2, how='outer', on='id').drop_duplicates()
Here is an equivalent way(I call it union-left here) that takes less time to compute:
df3 = df1.select('id').union(df2.select('id'))
df3 = df3.join(x1_df, how='left', on='id')
df3 = df3.join(x2_df, how='left', on='id').drop_duplicates()
The distribution of IDs in the two dataframes:
| df1 only | overlap | df2 only | |
|---|---|---|---|
| # of ids | 8625 | 914 | 8623 |
Here is the distribution of computing times for inner, left, outer, right and union-left(that gives same results as outer) joins(I repeated each join 20 times):
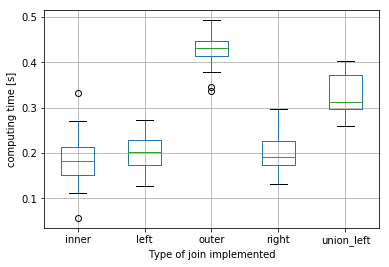
For these sizes of dataframes, the union-left join is on average ~20% faster than the equivalent outer join.